A feldolgozás 8 szakasza
Minden dokumentum egy többlépcsős, AI-vezérelt folyamaton halad végig — a biztonságos belépéstől a releváns találatok visszaadásáig.
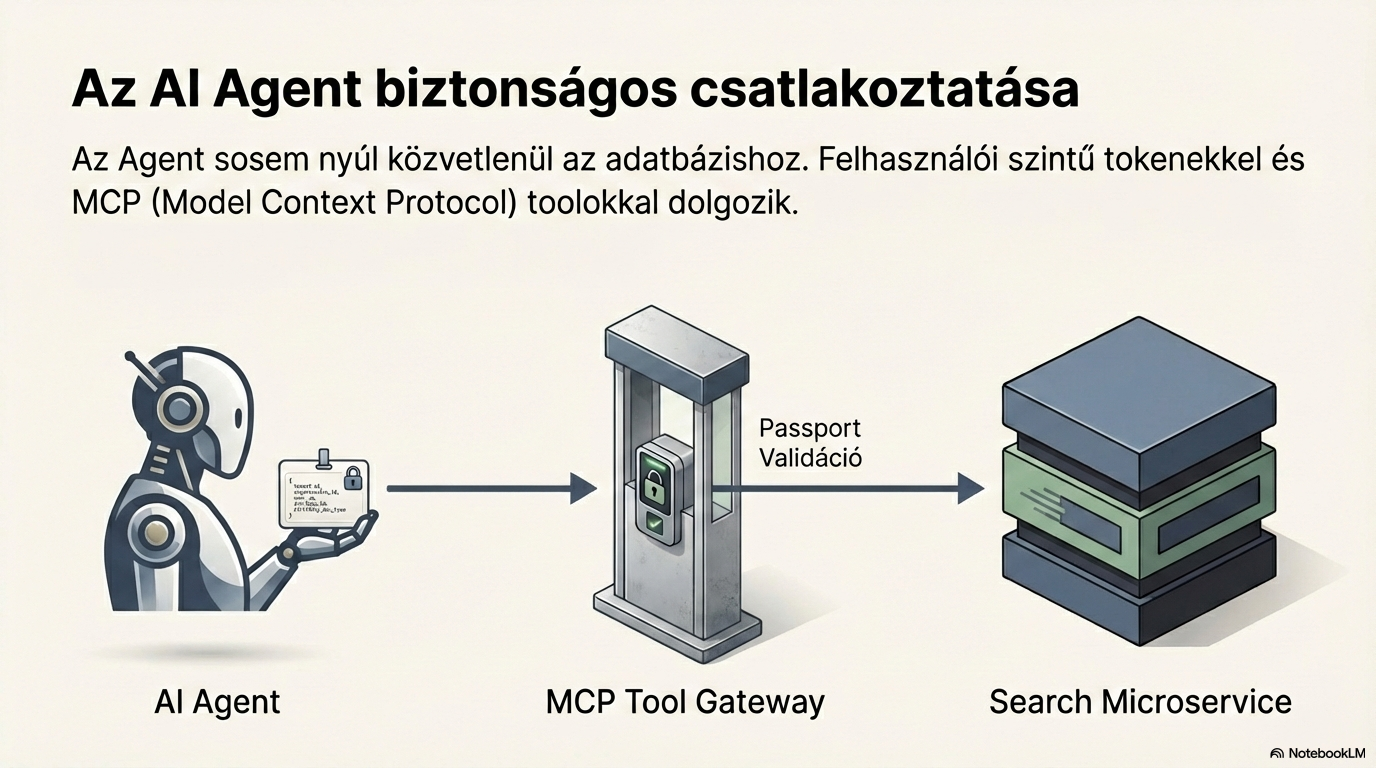
Jogosultságkezelés és szűrés
Biztonsági szűrés és hozzáférés-kezelés biztosítása a keresési és ügynöki funkciók számára. A Passport rendszer JSON-alapú jogosultságkezelést valósít meg.
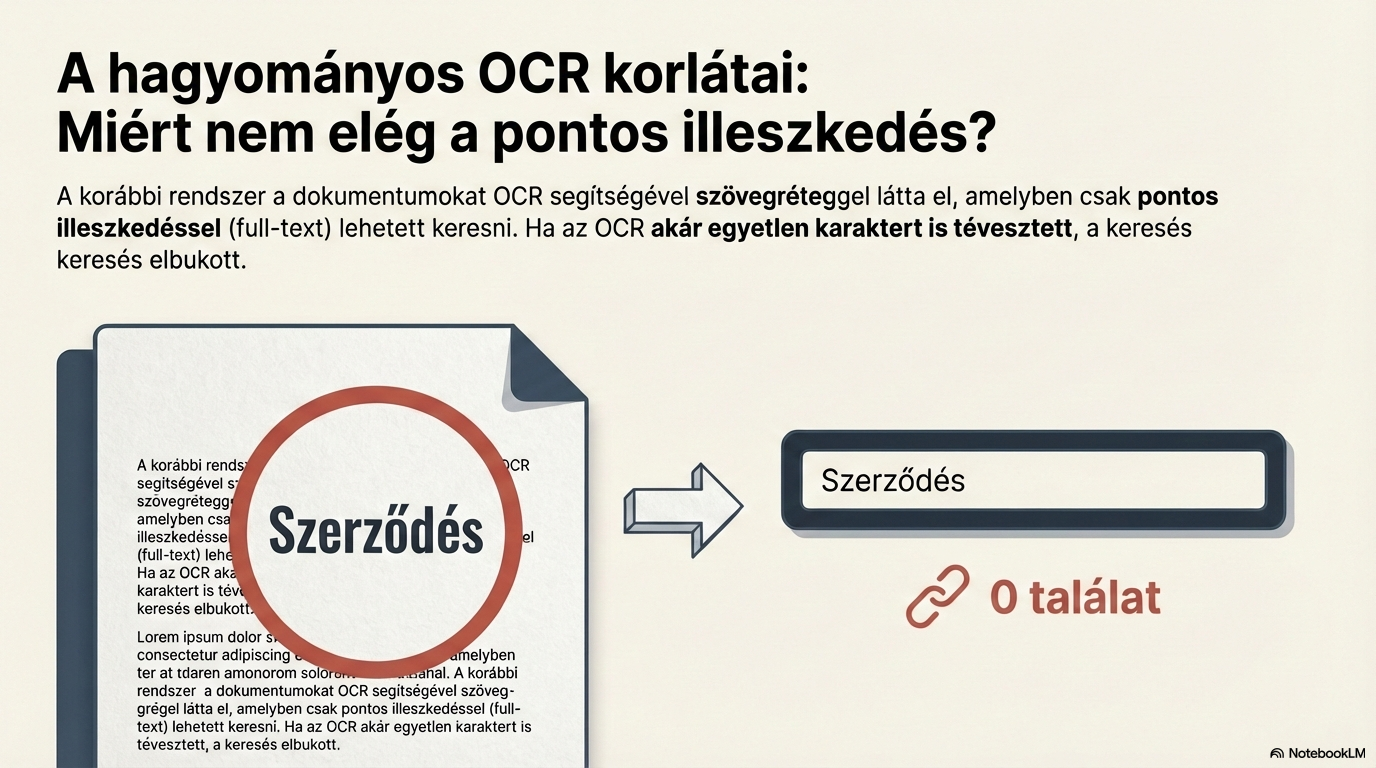
Alap dokumentumfeldolgozás
Karakterfelismerés és kereshető szövegréteg létrehozása a pontos illeszkedéshez. Az OCR technológia fizikai és digitális dokumentumokat egyaránt kezel.
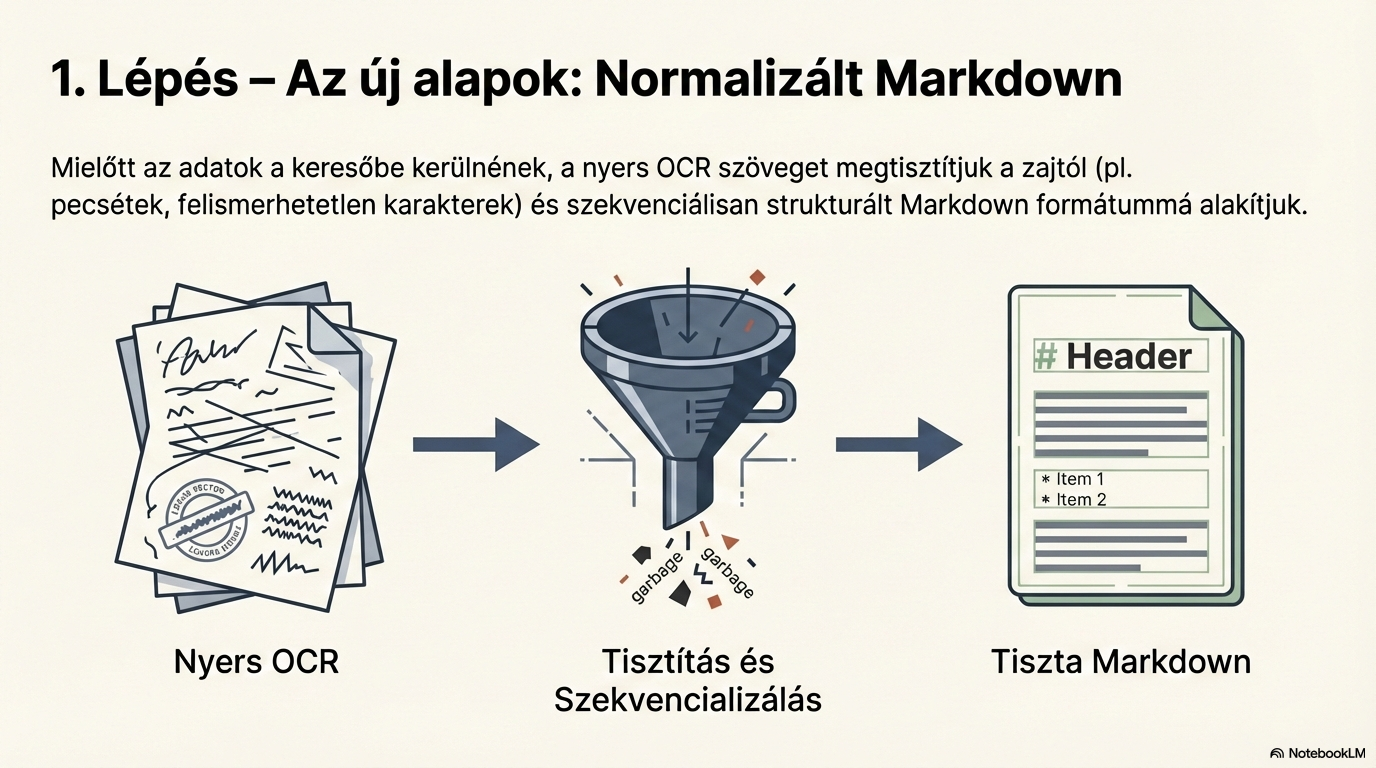
Szöveg normalizálás
Szétszórt szövegek struktúrába rendezése, zajszavak és redundáns karakterek eltávolítása. Markdown generálás és zajszűrés biztosítja a tiszta, strukturált szöveget.
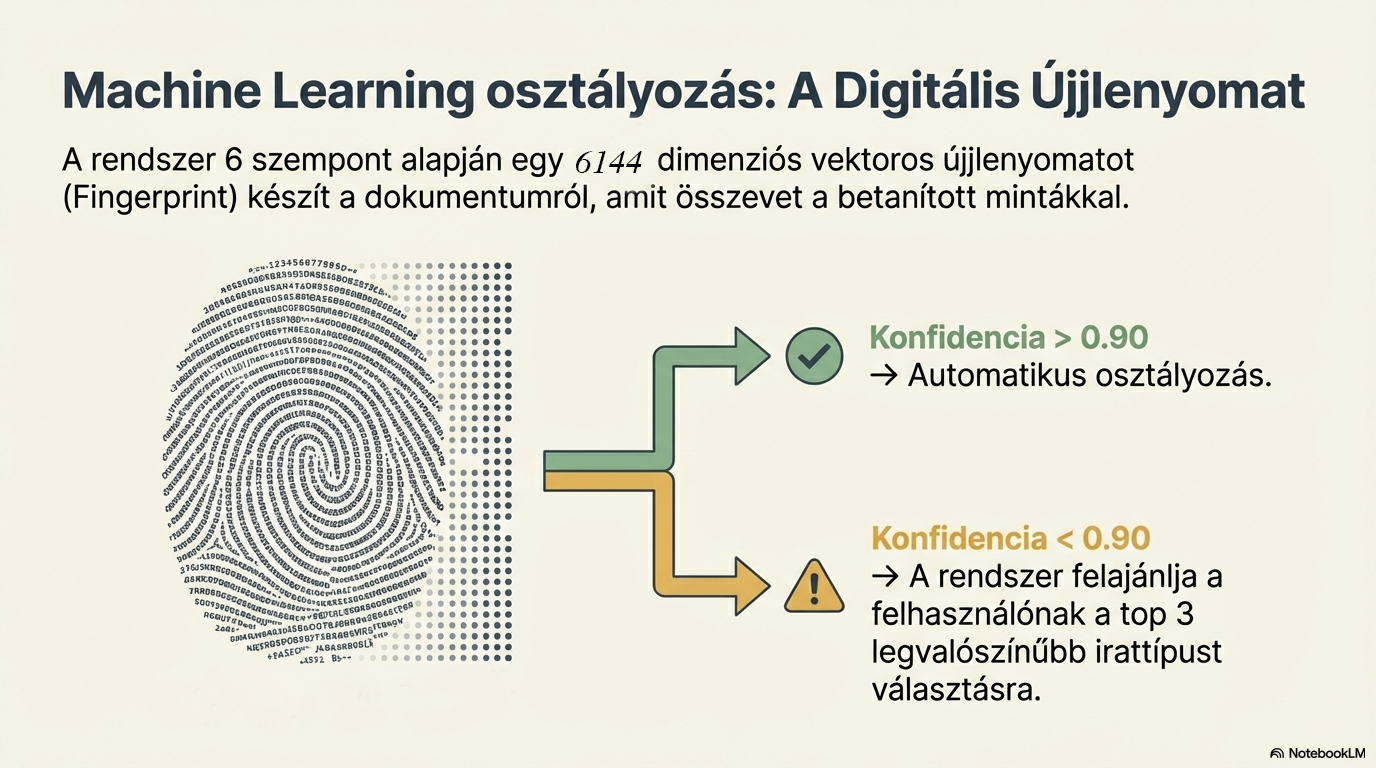
Irattípus felismerés
Automatikus irattípus meghatározás a megfelelő adatkinyerési sablonhoz. A gépi tanulási modell 6144 dimenziós vektoros ujjlenyomatot használ a pontos kategorizáláshoz.

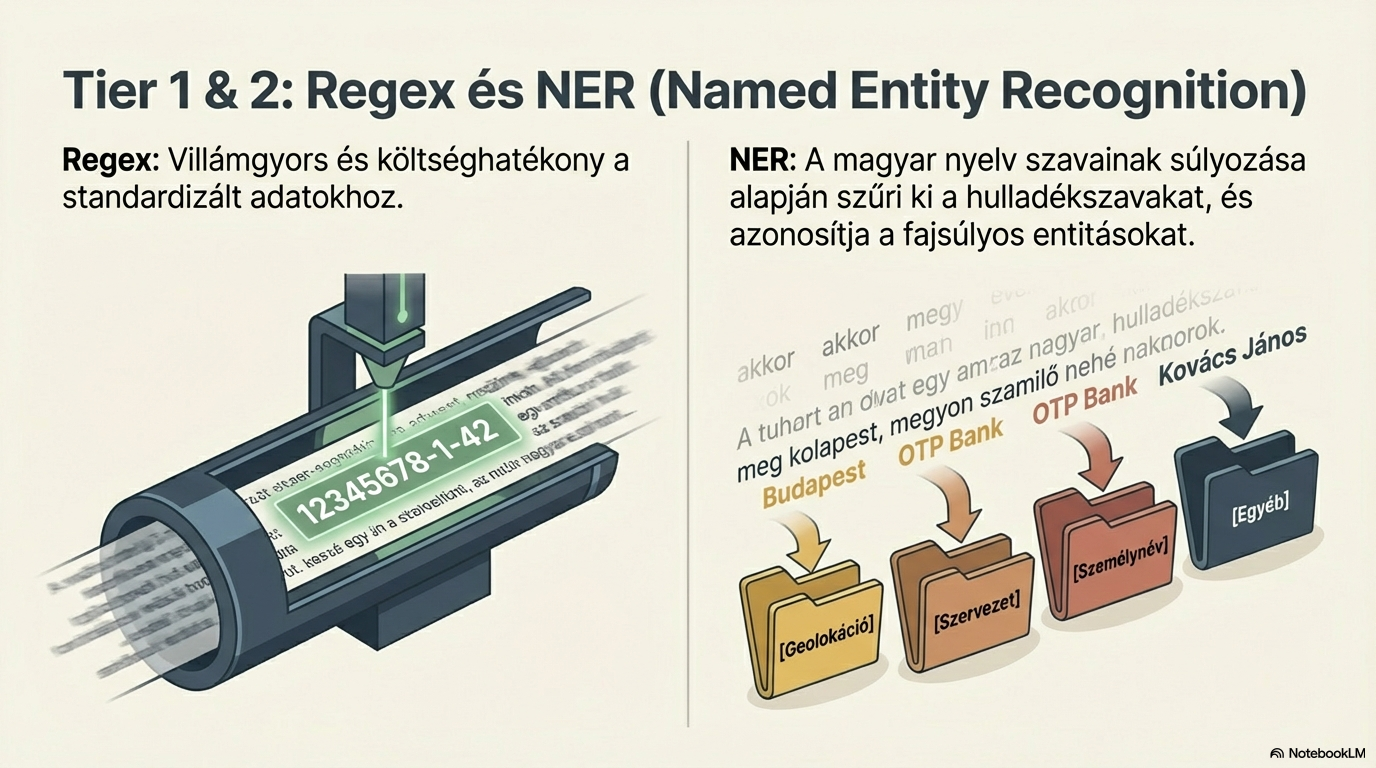
Strukturált adatkinyerés
Kulcsadatok — például adószám, végösszeg, nevek — kinyerése különböző szinteken. Regex, Named Entity Recognition és LLM együttes alkalmazásával.

Rugalmas (Elasztikus) keresés
Laza hasonlóságok és karakterelírások kezelése a keresési folyamat során. Az Elasticsearch / OpenSearch motor biztosítja a rugalmas szöveges keresést.
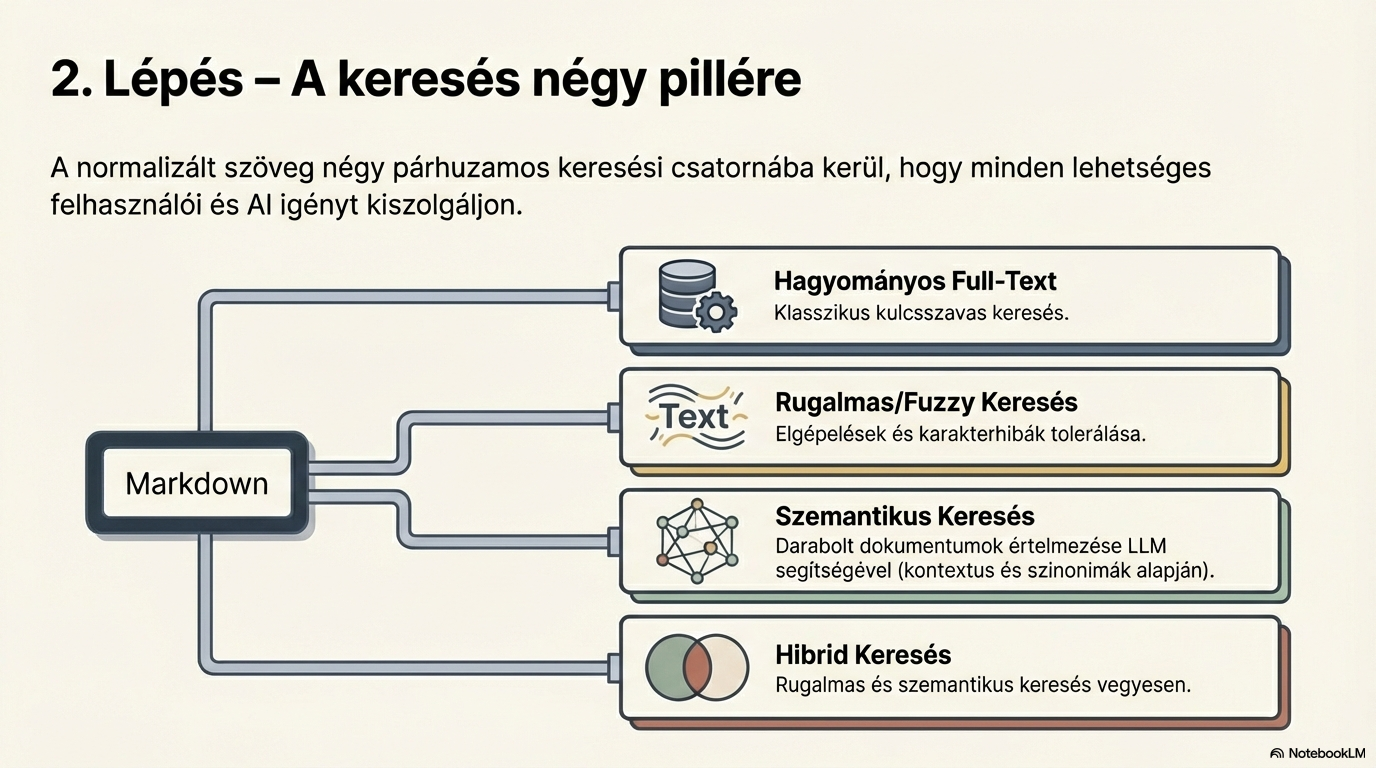
Szemantikus keresés
Értelem és kontextus alapú keresés, szinonimák és jelentéstartalom kezelése. A vektorizálás és a nagy nyelvi modell (LLM) biztosítja a mélyebb szövegértést.
Hibrid keresés (RAG előkészítés)
A két keresési mód találatainak egyesítése és a legrelevánsabb eredmények visszaadása. A rendszer a Top 30 találatból kiválasztja a 10 legpontosabbat.