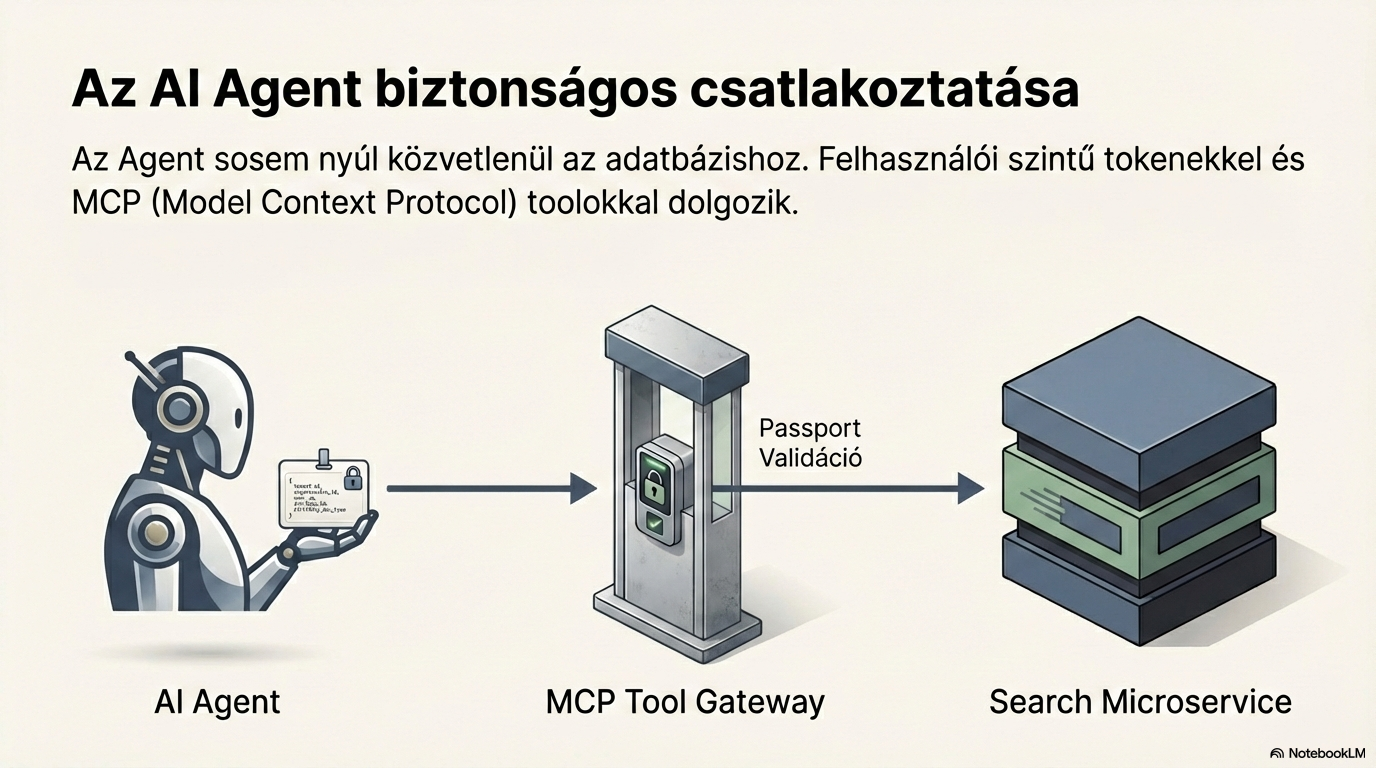
Jogosultságkezelés és szűrés
Minden keresés a jogosultságkezeléssel indul. A rendszer a Passport JSON-ből állapítja meg, hogy a felhasználó mely szervezethez tartozik, és milyen dokumentumokat érhet el. Így minden válasz csak azokat a dokumentumokat tartalmazza, amelyekhez a felhasználónak joga van.
InputKeresési kifejezés + Passport JSON
→
OutputSzűrt dokumentum ID lista
1
2
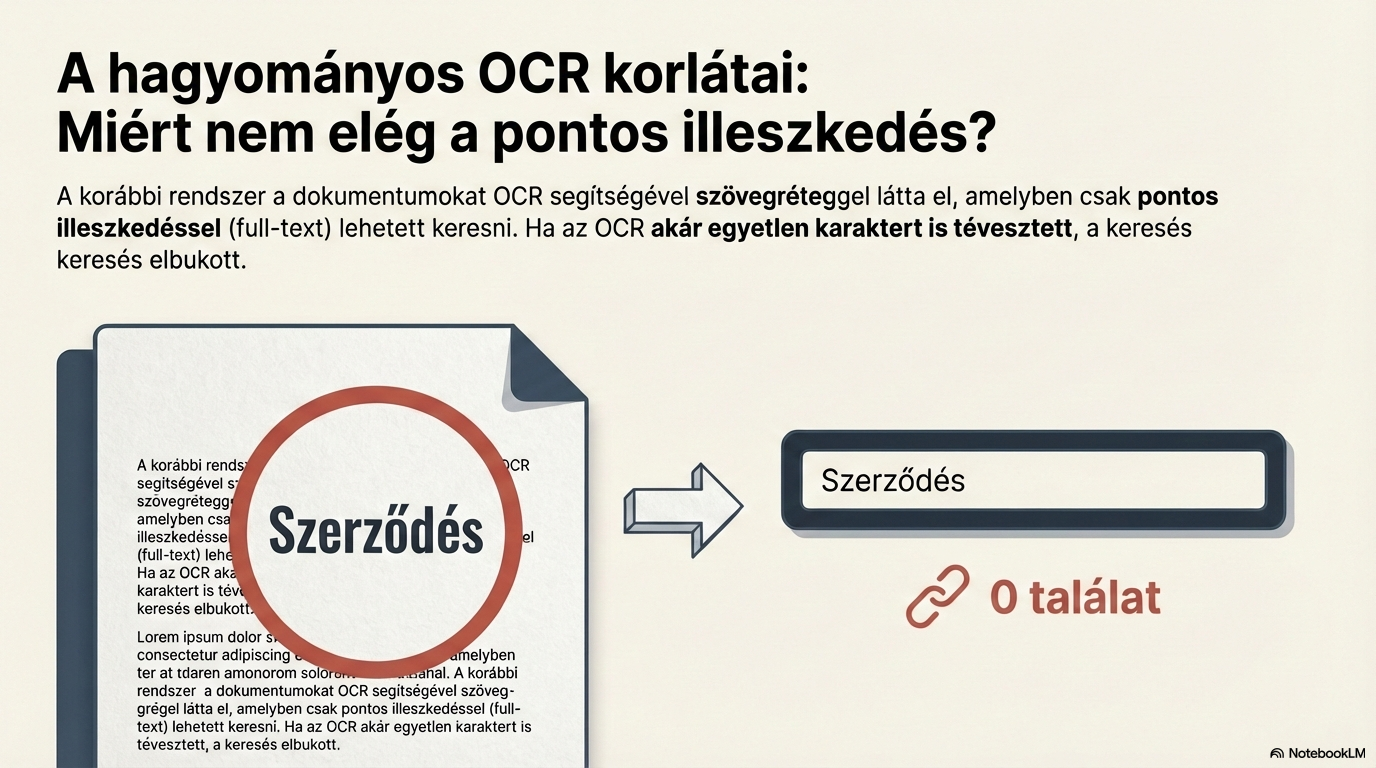
Alap dokumentumfeldolgozás (OCR)
A dokumentum szöveges rétegét karakterfelismeréssel (OCR) állítjuk elő. A szkennelt dokumentumoknál ez elengedhetetlen lépés — ez adja az alapot minden további feldolgozáshoz.
InputFizikai vagy digitális dokumentum
→
OutputSzövegréteg (Full text)
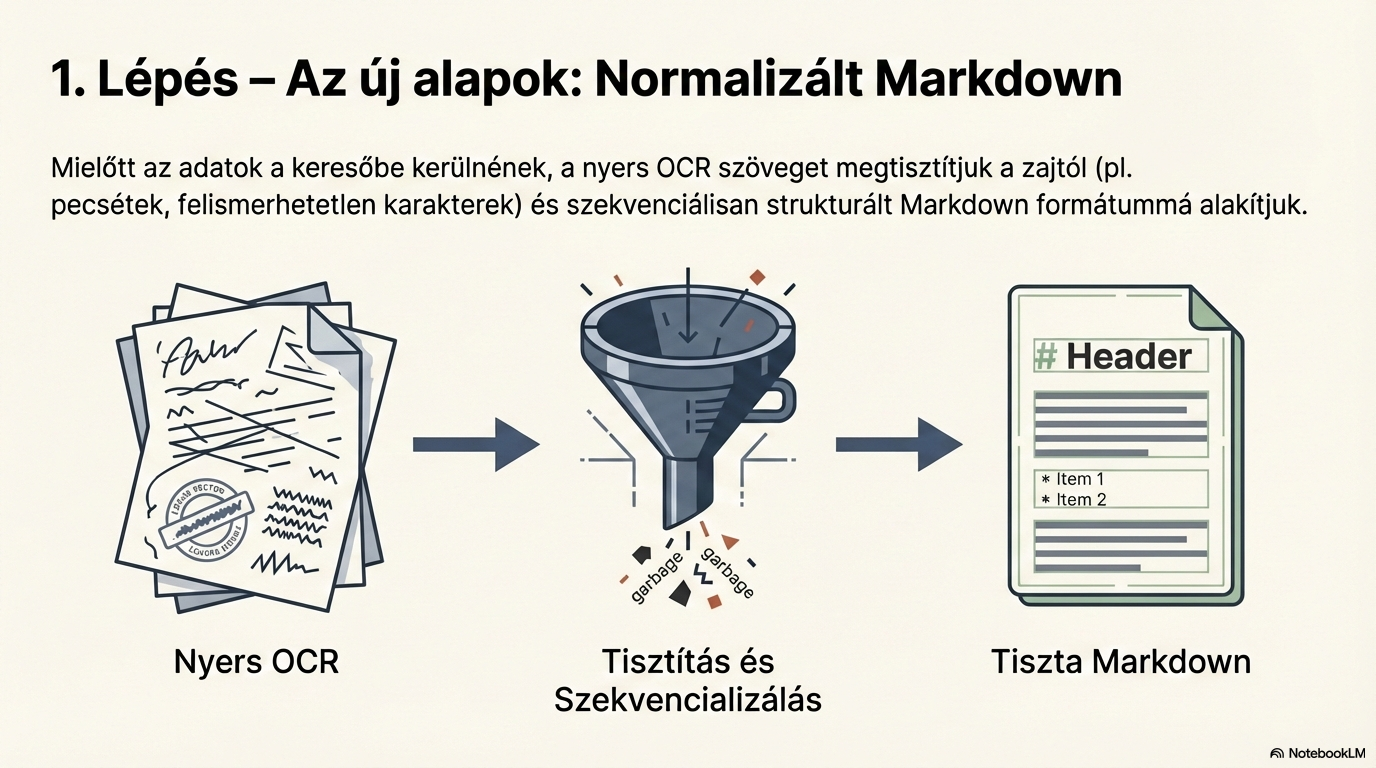
Szöveg normalizálás
Az OCR-ezett nyers szöveget strukturált Markdown formátumba alakítjuk. Eltávolítjuk a zajt (fejléc/lábléc ismétlődések, oldalszámok), és egységes, tiszta szöveget hozunk létre az MI feldolgozás számára.
InputOCR-ezett szöveg
→
OutputNormalizált Markdown dokumentum
3

4
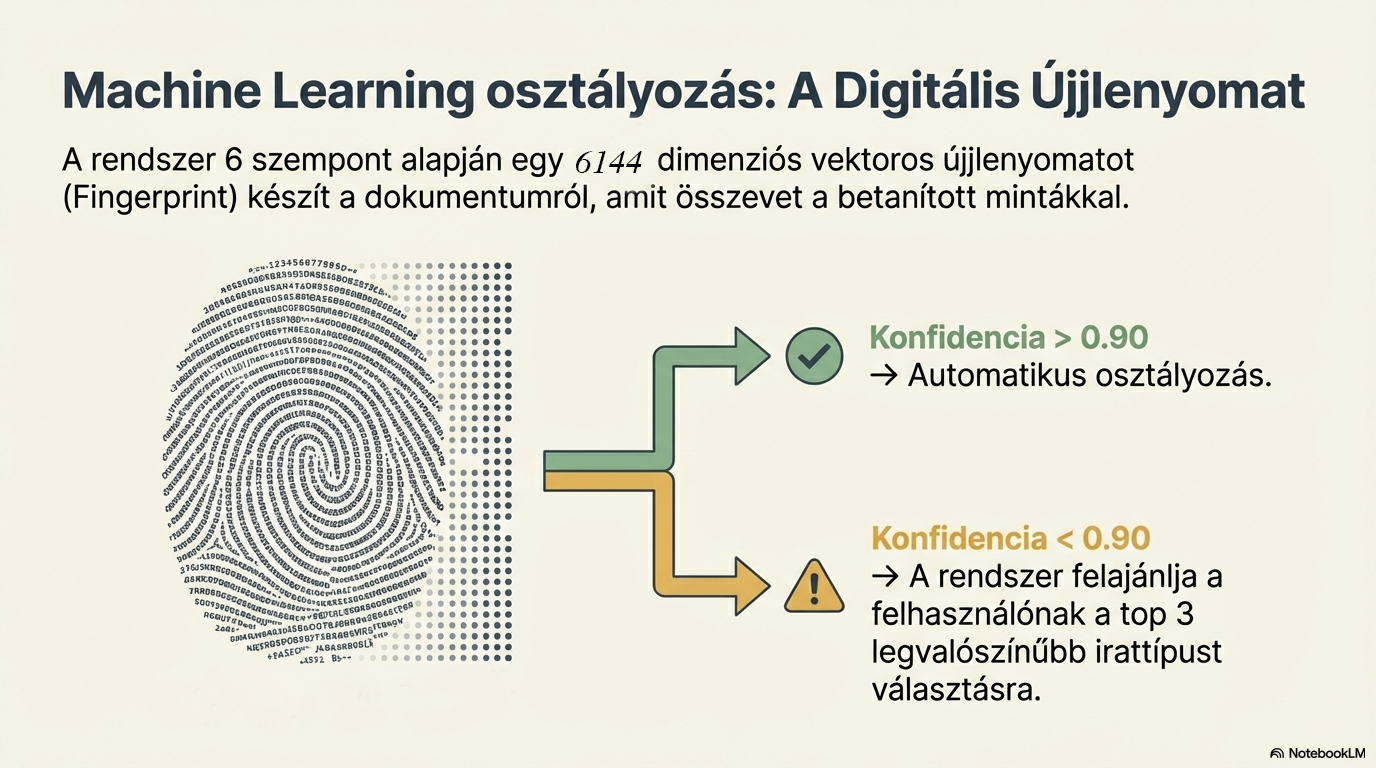
Irattípus felismerés
A dokumentumot 6144 dimenziós vektorrá (ujjlenyomattá) alakítjuk, majd gépi tanulással felismerjük a típusát. A rendszer összehasonlítja a tanított minták ujjlenyomataival, és 0,9–0,95 küszöbértékkel osztályoz.
Input6144 dimenziós vektor (ujjlenyomat)
→
OutputDokumentum típus (pl. számla)
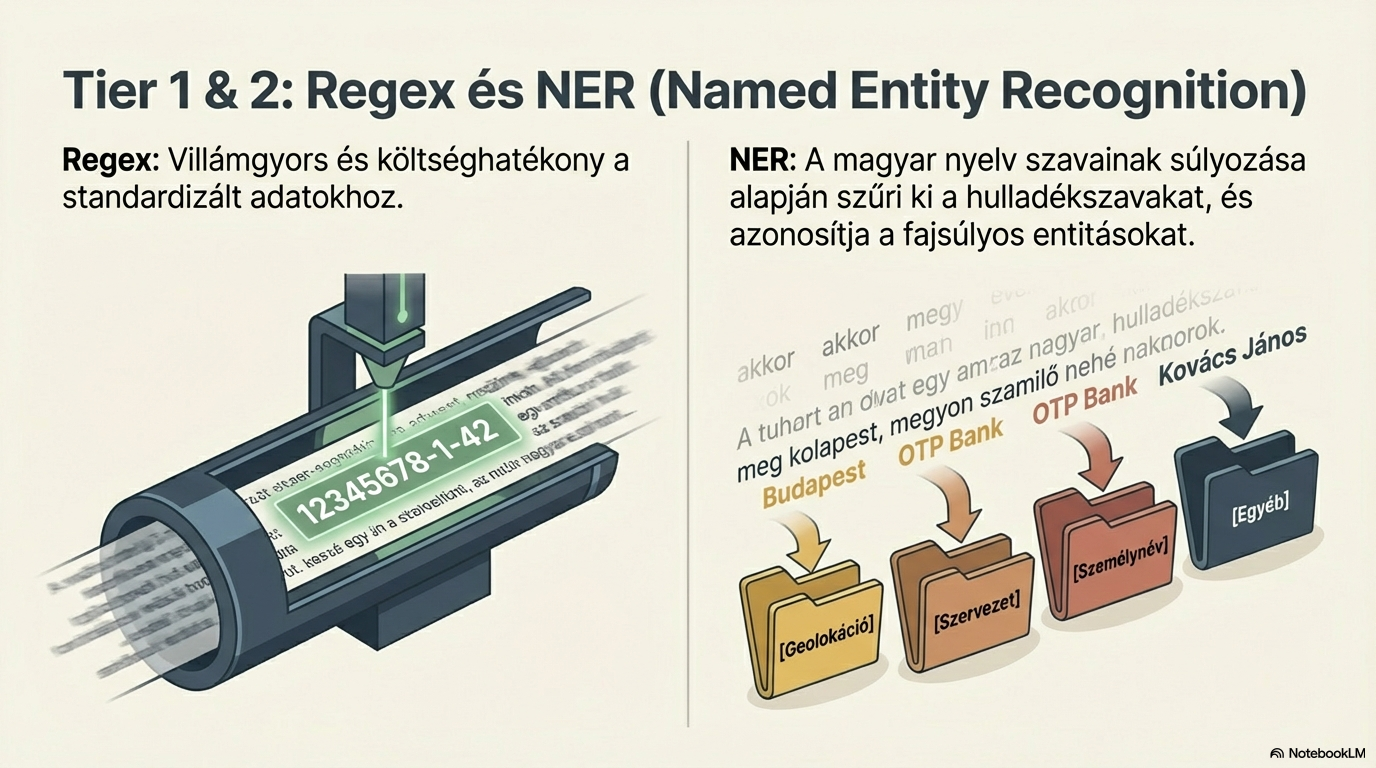
Strukturált adatkinyerés
A felismert irattípus alapján a rendszer kinyeri a kulcs-érték párokat: adószámot, összegeket, dátumokat, neveket. Három technikát kombinál: reguláris kifejezések, névelem-felismerés (NER) és LLM alapú kinyerés.
InputNormalizált Markdown szöveg
→
OutputKey-Value párok (strukturált mezők)
5

6
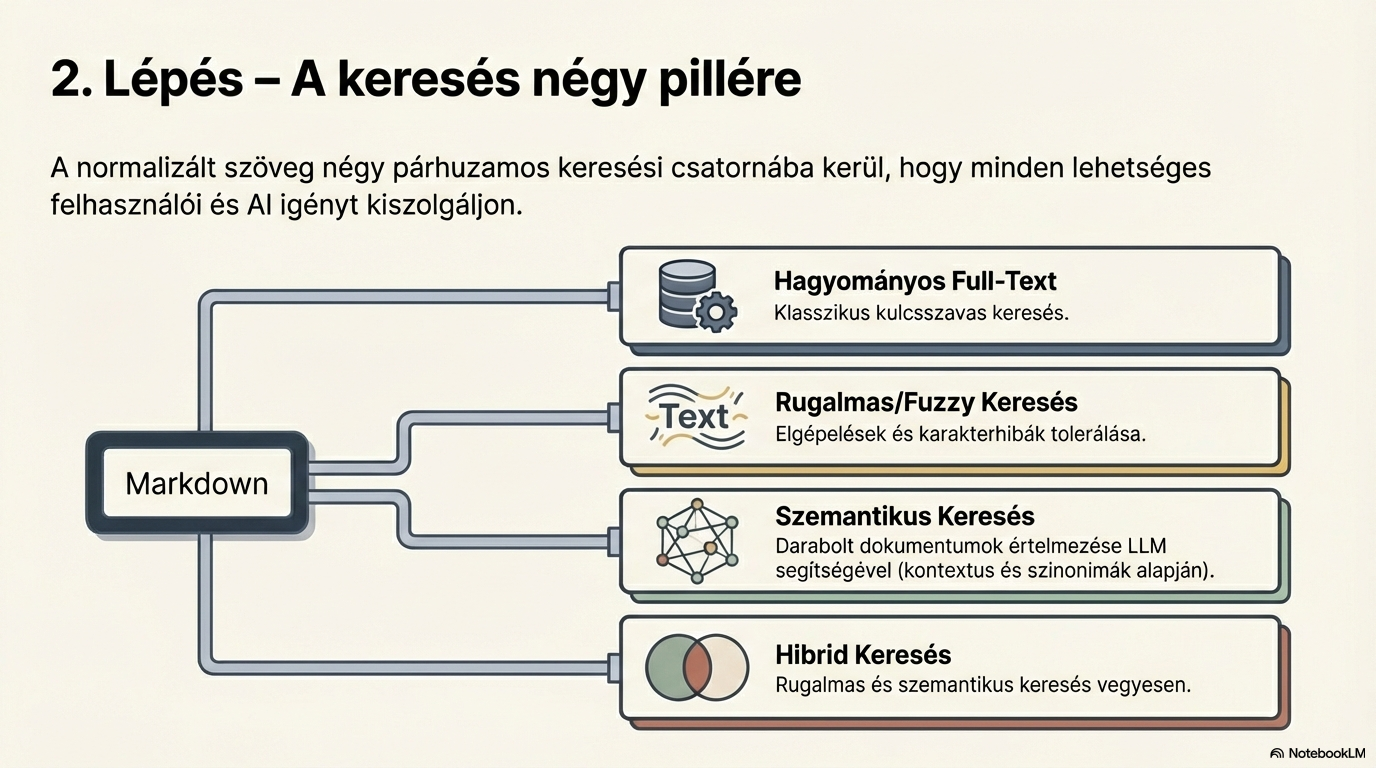
Rugalmas (Elasztikus) keresés
A normalizált szöveget Elasticsearch / OpenSearch indexbe helyezzük. Ez biztosítja a klasszikus szöveges keresést: pontos kifejezés, részleges egyezés, szűrők, és hasonlósági keresés a strukturált mezőkben.
InputNormalizált szöveg
→
OutputIndexelt dokumentumok
Szemantikus keresés
A dokumentumokat feldaraboljuk és vektorizáljuk: minden szövegdarabot 6144 dimenziós vektorrá alakítunk. Ezeket a Qdrant vektoros adatbázisban tároljuk, lehetővé téve a jelentés-alapú keresést — nem a szavak, hanem az értelmük alapján.
InputFeldarabolt dokumentum részek
→
OutputVektoros reprezentáció
7
8
Hibrid keresés (RAG előkészítés)
A végső lépésben az elasztikus és szemantikus keresési találatokat kombináljuk. Mindkét forrásból a legjobbakat összevonjuk és újrarangsoroljuk: az első körben 30 találatot választunk ki, majd ezekből a Top 10-et adjuk vissza a felhasználónak.
InputElasztikus és szemantikus találatok
→
OutputTop 10 rangsorolt találat